
We’re making it clearer how ChatGPT behaves and what we intend to do to make it better, while also enabling greater user customisation and increasing public participation in our decision-making process.
OpenAI’s mission is to guarantee that fake common insights (AGI)A benefits all of humankind. We subsequently think a parcel around the behavior of AI frameworks we construct within the run-up to AGI, and the way in which that behavior is decided. Since our dispatch of ChatGPT, clients have shared yields that they consider politically one-sided, hostile, or something else shocking. In numerous cases, we think that the concerns raised have been substantial and have revealed genuine confinements of our frameworks which we need to address. We’ve moreover seen many misinterpretations approximately how our frameworks and arrangements work together to shape the yields you get from ChatGPT.
Underneath, we summarize:
- How ChatGPT’s behavior is molded;
- How we arrange to progress ChatGPT’s default behavior;
- Our intent to permit more framework customization; and
- Our endeavors to urge more open input on our decision-making.
Where we are nowadays
Not at all like standard computer program, our models are enormous neural systems. Their behaviors are learned from a wide extend of information, not modified unequivocally. In spite of the fact that not a idealize relationship, the method is more comparative to preparing a puppy than to standard programming. An beginning “pre-training” stage comes to begin with, in which the show learns to anticipate the another word in a sentence, educated by its exposure to parcels of Web content (and to a endless cluster of points of view). This can be taken after by a moment stage in which we “fine-tune” our models to contract down framework behavior.
As of nowadays, this prepare is flawed. Now and then the fine-tuning handle falls brief of our aim (creating a secure and useful instrument) and the user’s expectation (getting a supportive yield in reaction to a given input). Making strides our strategies for aligning AI frameworks with human values could be a best need for our company, especially as AI frameworks gotten to be more competent.
A two step prepare: Pre-training and fine-tuning
The two fundamental steps included in building ChatGPT work as takes after:
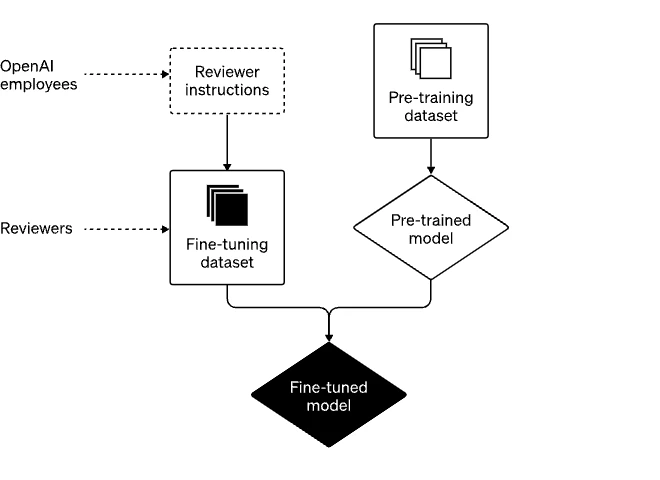
To begin with, we “pre-train” models by having them foresee what comes another in a enormous dataset that contains parts of the Web. They might learn to total the sentence “instead of turning cleared out, she turned _.” By learning from billions of sentences, our models learn linguistic use, numerous realities almost the world, and a few thinking capacities. They too learn a few of the predispositions display in those billions of sentences.
At that point, we “fine-tune” these models on a more limit dataset that we carefully produce with human commentators who take after rules that we offer them. Since we cannot anticipate all the conceivable inputs that future clients may put into our framework, we don’t compose nitty gritty informational for each input that ChatGPT will experience. Instead, we diagram a number of categories within the rules that our commentators utilize to survey and rate conceivable demonstrate yields for a extend of example inputs. At that point, whereas they are in utilize, the models generalize from this analyst criticism in arrange to reply to a wide cluster of particular inputs given by a given client.
The part of commentators and OpenAI’s approaches in framework advancement
In a few cases, we may provide direction to our analysts on a certain kind of yield (for illustration, “do not total demands for illicit content”). In other cases, the direction we share with analysts is more high-level (for case, “avoid taking a position on questionable topics”). Critically, our collaboration with commentators isn’t one-and-done—it’s an continuous relationship, in which we learn a part from their ability.
A huge portion of the fine-tuning prepare is keeping up a solid input circle with our analysts, which includes week after week gatherings to address questions they may have, or provide clarifications on our direction. This iterative criticism prepare is how we prepare the demonstrate to be superior and superior over time.
Taking prejudices into account
Numerous are appropriately stressed almost predispositions within the plan and affect of AI frameworks. We are committed to vigorously tending to this issue and being straightforward around both our eagerly and our advance. Towards that conclusion, we are sharing a parcel of our guidelines(opens in a modern window) that relate to political and disputable points. Our rules are express that commentators ought to not favor any political bunch. Predispositions that nevertheless may rise from the method portrayed over are bugs, not highlights.
Whereas contradictions will continuously exist, we trust sharing this web journal post and these enlightening will provide more knowledge into how we see this basic viewpoint of such a foundational innovation. It’s our conviction that innovation companies must be responsible for creating arrangements that stand up to investigation.
We’re continuously working to make strides the clarity of these guidelines—and based on what we’ve learned from the ChatGPT dispatch so distant, we’re planning to give clearer enlightening to analysts around potential pitfalls and challenges tied to inclination, as well as disputable figures and subjects. Also, as portion of progressing straightforwardness activities, we are working to share totaled statistic data almost our analysts in a way that doesn’t damage security rules and standards, since this is an extra source of potential predisposition in framework yields.
We are as of now investigating how to form the fine-tuning prepare more reasonable and controllable, and are building on outside progresses such as run the show based rewards(opens in a unused window) and Protected AI(opens in a unused window).
Our direction: The foundational elements of forthcoming systems
In interest of our mission, we’re committed to guaranteeing that get to to, benefits from, and impact over AI and AGI are broad. We accept there are at slightest three building squares required in arrange to realize these objectives within the setting of AI framework behavior.B
- Make strides default behavior. We need as numerous clients as conceivable to discover our AI frameworks valuable to them “out of the box” and to feel that our innovation gets it and regards their values.
Towards that conclusion, we are contributing in inquire about and building to diminish both dazzling and unpretentious predispositions in how ChatGPT reacts to diverse inputs. In a few cases ChatGPT as of now denies yields that it shouldn’t, and in a few cases, it doesn’t deny when it ought to. We accept that enhancement in both regards is conceivable.
Furthermore, we have room for advancement in other measurements of framework behavior such as the framework “making things up.” Criticism from clients is important for making these enhancements.
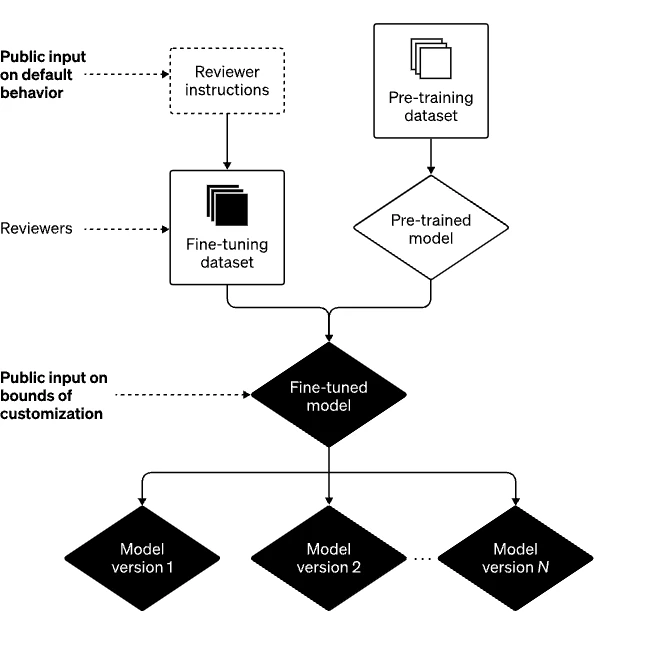
- Characterize your AI’s values, inside wide bounds: We accept that AI ought to be a valuable instrument for person individuals, and hence customizable by each client up to limits characterized by society. Hence, we are creating an overhaul to ChatGPT to permit clients to effectively customize its behavior.
This will cruel permitting framework yields that other individuals (ourselves included) may strongly disagree with. Striking the right adjust here will be challenging–taking customization to the extraordinary would hazard empowering pernicious employments of our innovation and sycophantic AIs that thoughtlessly open up people’s existing convictions.
There will subsequently continuously be a few bounds on framework behavior. The challenge is characterizing what those bounds are. In the event that we attempt to create all of these judgments on our possess, or on the off chance that we attempt to create a single, solid AI system, we’ll be coming up short within the commitment we make in our Constitution to “avoid undue concentration of power.”
- Open input on defaults and difficult bounds: One way to dodge undue concentration of control is to allow individuals who utilize or are influenced by frameworks like ChatGPT the capacity to impact those systems’ rules.
We accept that numerous decisions about our defaults and difficult bounds ought to be made collectively, and whereas down to earth execution may be a challenge, we point to incorporate as numerous viewpoints as conceivable. As a beginning point, we’ve looked for outside input on our innovation within the shape of ruddy teaming(opens in a unused window). We too as of late started requesting open input(opens in a modern window) on AI in instruction (one especially critical setting in which our innovation is being sent).
We are within the early stages of guiding endeavors to request open input on points like framework behavior, divulgence components (such as watermarking), and our arrangement approaches more broadly. We are also investigating associations with outside organizations to conduct third-party reviews of our security and arrangement endeavors.
In summary
When the three aforementioned building blocks are combined, the future we envision looks like this:
We will all make blunders from time to time. As a result, we will refine our models and processes and take lessons from them.
We value the public’s and the ChatGPT user community’s attentiveness in holding us responsible, and we can’t wait to provide additional details about our work in the aforementioned three areas in the months to come.
Please apply for subsidized access to our API via the Researcher Access Program (opens in a new window) if you are interested in conducting research to help realize this vision, including but not limited to research on alignment, fairness and representation, and sociotechnical research to understand the impact of AI on society.
No Responses